Analyse der Altersstruktur des SCR Altach-Kaders

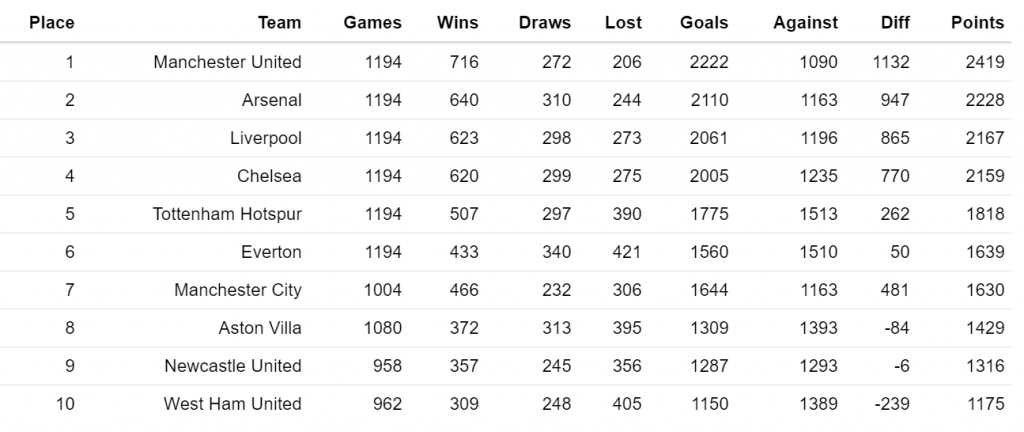
Ich habe die Altersstruktur des Kaders des SC Rheindorf Altach analysiert und die Ergebnisse in einer Grafik visualisiert, die das Alter der Spieler mit ihrem Anteil an den Einsatzminuten der vergangenen Saison vergleicht. Diese Gegenüberstellung zeigt interessante Trends und Einblicke in die strategische Ausrichtung des Vereins.
Philipp Netzer ist mit Abstand der älteste Spieler im Kader. Aufgrund einer Verletzung konnte er nur eine sehr begrenzte Anzahl an Minuten auf dem Platz stehen. Trotz seiner eingeschränkten Einsatzzeit entschied sich der Verein, seinen Vertrag um ein weiteres Jahr zu verlängern – eine Entscheidung, die auf seine Führungserfahrung und Bedeutung für das Team hinweisen könnte.
Martin Kobras, der Torhüter und Dauerbrenner des Teams, nimmt weiterhin eine Schlüsselrolle ein. Bisher gibt es im Kader keinen ernsthaften Konkurrenten, der seine Position als Nummer 1 gefährden könnte. Der 24-jährige Tino Casali, der kürzlich verpflichtet wurde, könnte langfristig jedoch eine Option sein, um Kobras in Zukunft zu ersetzen.
Besonders spannend sind die jungen Vorarlberger Talente Johannes Tartarotti und Lars Nussbaumer. Beide stehen noch am Anfang ihrer Karriere und besitzen das Potenzial, sich in den kommenden Jahren zu Schlüsselspielern zu entwickeln, da sie sich nun in das optimale Fußballeralter bewegen.
Die Statistik zeigt, dass das Durchschnittsalter der eingesetzten Spieler in der letzten Saison bei 24,9 Jahren lag. Damit positioniert sich der SCR Altach zwischen den älteren und jüngeren Teams der Liga: Während der Wolfsberger AC mit 27,5 Jahren den ältesten Kader stellte, setzte Red Bull Salzburg mit einem Durchschnittsalter von 23,5 Jahren auf Jugend und Dynamik.